
Kajian Spatio-Temporal Sebaran Vegetasi Di Sekitar UII
dengan Pendekatan Machine Learning
Achmad Fauzan*, Dina Tri Utari1, Hannura Adriana1, Alifia Tanza1
Department of Statistics, Faculty of Mathematics and Natural Sciences, Universitas Islam Indonesia
*Email: [email protected]
Latar Belakang
Citra satelit memberikan informasi berharga tentang aspek permukaan bumi, seperti penggunaan/tutupan lahan, kondisi lingkungan, dan perubahan dari waktu ke waktu. Namun, menafsirkan dan mengekstraksi informasi bermakna dari gambar-gambar ini secara akurat dapat menjadi tantangan karena sifatnya yang kompleks dan dinamis. Teknik machine learning telah menunjukkan potensi besar dalam menganalisis dan memodelkan data variabel spasial dan temporal, termasuk citra satelit. Algoritma ini dapat menangkap ketergantungan spasial, temporal, dan spatio-temporal melalui pembelajaran representasi fitur otomatis. Dengan memanfaatkan algoritma machine learning, peneliti mengembangkan model yang dapat secara efektif mengklasifikasikan dan memprediksi berbagai fitur dan fenomena pada citra satelit. Pada penelitian ini, kami berfokus pada pengklasifikasian data geospasial citra satelit Sentinel level 2-A dengan menggunakan pendekatan machine learning seperti Support Vector Machine, Naive Bayes, dan Decision Tree pada objek vegetasi di sekitar Universitas Islam Indonesia (UII) dari tahun 2019 hingga tahun 2023.
metodologi
Tahapan penelitian yang dilakukan adalah sebagai berikut.
- Pengambilan data melalui Google Earth Engine (https://earthengine.google.com/). Data yang digunakan adalah data citra satelit dari Sentinel level 2-A dengan resolusi spasial 10 meter, maknanya adalah setiap 1-pixel mewakili objek yang berukuran 10×10-meter pada kondisi riilnya. Selanjutnya dari data ini dilakukan preprocessing menggunakan QGIS dan R Studio.
- Melakukan clipping atau pemotongan menggunakan polygon area yang berbatasan langsung dengan Universitas Islam Indonesia.
- Membuat sampel data training dan testing dengan melakukan random point di daerah yang sudah didigitasi.
- Melakukan analisis klasifikasi dan dilakukan iterasi. Variabel yang digunakan dalam penelitian ada 5 variabel yaitu: variabel x sebagai UTM easting, variabel y sebagai UTM northing, variabel bebas/X yaitu band 8 dan band 4, dan variabel terikat/Y yaitu kelas (vegetasi maupun non vegetasi).
Hasil
Tahapan yang dilakukan pertama adalah pre-processing. Pada tahapan ini akan dilakukan pemotongan data berdasarkan area yang akan digunakan. Berikut ilustrasi dari visualisasi band 4 dan band 8 yang diperoleh.


Gambar 1. Data Raster dari Band 4 dan 8
Berdasarkan Gambar 1. dada raster band 4 terlihat seperti gambar hitam dan raster band 8 seperti abu-abu karena pada band 4 memiliki panjang gelombang 665nm, sedangkan pada raster band 8 memiliki Panjang gelombang 842 nm. Panjang gelombang dengan rentang tersebut masuk dalam panjang gelombang cahaya tampak yang peka oleh retina mata, namun tidak terlihat semua dengan jelas pada indera penglihatan manusia. Dalam membuat data training dan testing pada penelitian ini akan dilakukan pembangkitan data sebanyak 1000 titik random dari hasil digitasi non-vegetasi dan 1000 titik random dari hasil digitasi vegetasi sehingga didapatkan total keseluruhan data sebesar 2000 titik. Pembuatan digitasi non-vegetasi dan vegetasi dilakukan dengan membuat polygon menggunakan QGIS sehingga didapatkan data lapangan.
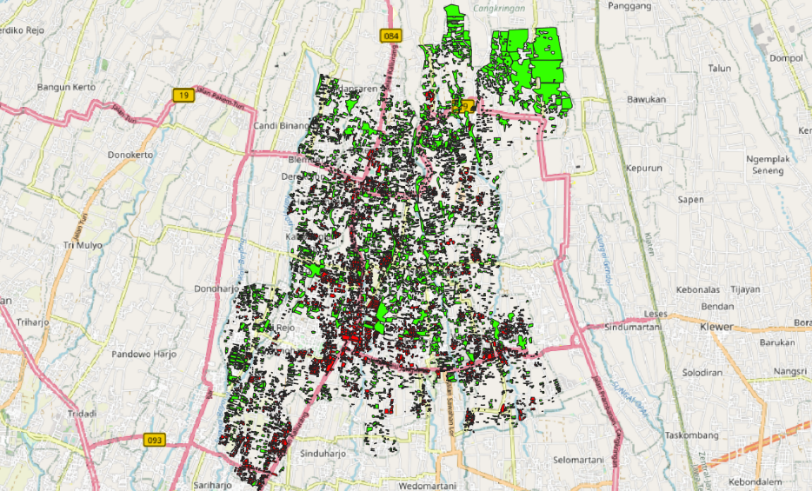
Gambar 2. Hasil Digitasi Non-Vegetasi dan Vegetasi
Gambar 2. merupakan hasil digitasi non-vegetasi dan vegetasi dengan warna merah menyatakan non-vegetasi dan warna hijau menyatakan vegetasi. Pada data non-vegetasi akan diberi label dengan angka 0 dan pada data vegetasi akan diberi label dengan angka 1. Pembagian data training dan testing akan dibagi menjadi 80:20.
Selanjutnya klasifikasi kawasan vegetasi dan non-vegetasi dilakukan berdasarkan variabel-variabel terkait. Metode terbaik yang diperoleh adalah metode Naïve Bayes berdasarkan selisih rata-rata antara data training dan data testing pada nilai akurasi sebesar 0.12, sedangkan pada metode Support Vector Machine memiliki selisih sebesar 0.16 dan metode Decision Tree memiliki selisih sebesar 0.68. Ilustrasi dari hasil prediksi dataset disajikan pada Gambar 3.


Gambar 3. Visualisasi Hasil Prediksi Dataset 2023
Gambar 3 menunjukan visualisasi prediksi dataset pada tahun 2023. Daerah yang berwarna hijau dikategorikan sebagai objek vegetasi, sementara daerah berwarna putih sebagai objek non vegetasi. Dari gambar 3 nampak prediksi sudah sesuai dengan data riilnya. Nilai akurasi data training pada hasil identifikasi vegetasi dan non-vegetasi pada daerah yang berbatasan langsung dengan UII pada tahun 2019 hingga 2023 menggunakan Naïve Bayes secara berturut-turut sebesar 94%, 93.75%, 92.31%, 90.12%, dan 92.19% sedangkan nilai akurasi pada data testing sebesar 95.25%, 93%, 91.25%, 91.5%, dan 94%. Berdasarkan hasil yang diperoleh, dari tahun ke tahun persentase vegetasi disekitar UII mengalami penurunan hingga 2% dari seluruh areal yang diamati.
Rekomendasi
Jika dilihat dari aspek satu waktu, diperoleh hasil penelitian diperoleh perkembangan proporsi kawasan vegetasi dari penurunan yang siginifikan berdasarkan radius antara 0.5 hingga 7 km yang artinya semakin dekat dengan Masjid Ulil Albab UII maka semakin sedikit lahan vegetasi, sebaliknya semakin jauh dengan Masjid Ulil Albab UII maka semakin banyak lahan vegetasi. Sementara jika dilihat dari aspek lebih dari multi waktu, tahun 2023 memiliki jumlah lahan vegetasi lebih sedikit dibandingkan tahun-tahun sebelumnya. Maka dari itu, semakin bertambahnya tahun semakin banyak pembangunan disekitar UII. Berdasarkan fenomena tersebut, dapat dipertimbangkan pola Pembangunan yang lebih terpola sehingga tidak merusak sumberdaya yang lain.
Ucapan Terimakasih
Penulis mengucapkan terima kasih kepada Badan Perencanaan dan Pengembangan/ Rumah Gagasan Universitas Islam Indonesia atas dukungan yang berharga dalam penelitian ini.


